Bạn đang xem: Phân tích nhân tố trong spss

Giá trị hội tụ: những biến quan gần kề cùng đặc điểm hội tụ về và một nhân tố, khi màn trình diễn trong ma trận xoay, các biến này vẫn nằm bình thường một cột với nhau.Giá trị phân biệt: các biến quan liêu sát quy tụ về nhân tố này và buộc phải phân biệt với những biến quan tiền sát quy tụ ở yếu tố khác, khi biểu diễn trong ma trận xoay, từng nhóm biến chuyển sẽ bóc thành từng cột riêng rẽ biệt.

Đưa trở thành quan sát của các biến chủ quyền cần thực hiện đối chiếu EFA vào mục Variables, nếu gồm biến quan cạnh bên nào bị loại bỏ ở bước trước đó, bọn họ sẽ không đưa vào so sánh EFA. để ý 4 tùy chọn lựa được đánh số ở ảnh bên dưới.

- Descriptives: Tích vào mục KMO & Barlett’s test of sphericity nhằm xuất bảng báo giá trị KMO và quý giá sig của chu chỉnh Barlett. Nhấp Continue để trở về cửa sổ ban đầu.

- Extraction: Ở đây, họ sẽ áp dụng phép trích PCA (Principal Components Analysis). Với SPSS đôi mươi và các phiên bạn dạng 21, 22, 23, 24, PCA sẽ tiến hành viết gọn lại là Principal Components như hình hình ảnh bên dưới, đây cũng là tùy lựa chọn mặc định của SPSS. Cạnh bên PCA, bọn họ cũng thường sử dụng PAF, cách dùng nhị phép quay phổ cập này, các bạn cũng có thể xem tại bài bác viếtPhép trích Principal Components Analysis (PCA) với Principal Axis Factoring (PAF).

Khi những bạn bấm chuột vào nút mũi tên phía xuống sẽ có rất nhiều tùy chọn phép trích không giống nhau. Số lượng yếu tố được trích ra ở ma trận xoay phụ thuộc vào khá những vào vấn đề lựa chọn phép trích, mặc dù nhiên, tư liệu này vẫn chỉ triệu tập vào phần PCA.
- Rotation: Ở phía trên có các phép quay, thường bọn họ hay sử dụng Varimax cùng Promax. Riêng với dạng đề bài đã khẳng định được biến chủ quyền và phát triển thành phụ thuộc, họ sử dụng phép tảo Varimax. Chúng ta cũng có thể tìm đọc sự khác biệt cũng như khi nào dùng phép xoay như thế nào tại nội dung bài viết Phép cù vuông góc Varimax với phép quay ko vuông góc Promax. Nhấp Continue để quay lại cửa sổ ban đầu.

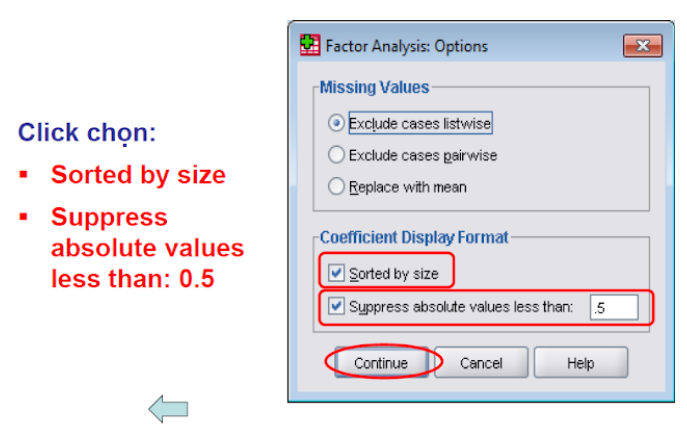
- Options:Tích vào Sorted by size để ma trận xoay sắp xếp thành từng cột dạng lan can để dễ dàng đọc tác dụng hơn, bạn cũng có thể tích hoặc ko tích, việc này không tác động đến kết quả. Cần nhớ rằng, thứ tự các yếu tố trong tác dụng ma trận chuyển phiên không phản ảnh mức độ đặc biệt quan trọng của yếu tố đó. Với mục Suppress small coefficients, còn nếu không tích chọn, ma trận xoay sẽ hiển thị toàn cục hệ số cài đặt của mỗi biến chuyển quan sát ở từng nhân tố.


Tại hành lang cửa số tiếp theo,chọn OK nhằm xuất công dụng ra output.

Có khá nhiều bảng ở output, tất cả các bảngnày đều đóng góp vào việc đánh giá hiệu quả phân tích EFA là giỏi hay tệ. Tuynhiên, ngơi nghỉ đây người sáng tác tập trung vào bố bảng hiệu quả chính: KMO and
Barlett’s Test, Total Variance Explained với Rotated Component Matrix, bởi áp dụng ba bảng này họ đã có thể đánh giáđược kết quả phân tích EFA tương xứng hay không phù hợp.


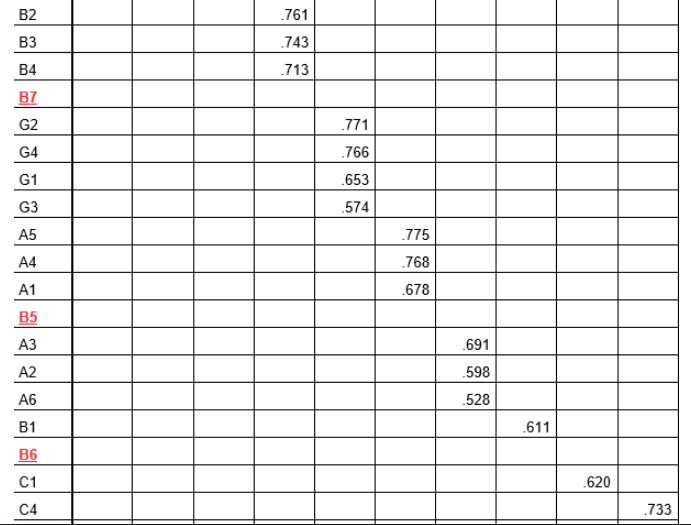
Kết quả lần EFA đầu tiên: KMO = 0.887 >0.5, sig Bartlett’s test = 0.000 thực hiện ngưỡng thông số tải là 0.5 thay vì chọn thông số tải tương ứng theo kích cỡ mẫu. đối chiếu ngưỡng này với công dụng ở ma trậnxoay, gồm hai trở thành xấu là DN4 và LD5 yêu cầu xem xét các loại bỏ:
Biến DN4 mua lên ở cả hai nhân tố là Component 4 cùng Component 6 với thông số tải theo thứ tự là 0.612 với 0.530, mức chênh lệch thông số tải bằng 0.612 – 0.530 = 0.082 biến chuyển LD5 có thông số tải ở tất cả các nhân tố đều bé dại 0.5.Tác giả áp dụng phương thức các loại một lượt cácbiến xấu trong một lần so với EFA. Trường đoản cú 28 thay đổi quan giáp ở lần so với EFAthứ nhất, loại trừ DN4 và LD5 và gửi 26 thay đổi quan sát còn sót lại vào so sánh EFAlần đồ vật hai.


Có 6 nhân tố được trích nhờ vào tiêu chí eigenvaluelớn hơn 1, bởi thế 6 yếu tố này bắt tắt thông tin của 26 thay đổi quan cạnh bên đưa vào
EFA một cách tốt nhất. Tổng phương sai mà lại 6 nhân tố này trích được là 63.357% > 50%, như vậy,6 yếu tố được trích giải thích được 63.357% trở thành thiên dữ liệu của 26 biếnquan gần cạnh tham gia vào EFA.

Kết quả ma trận xoay mang lại thấy, 26 biến chuyển quan gần kề được phân thành 6 nhân tố, toàn bộ các phát triển thành quan sát đều có hệ số tải yếu tố Factor Loading to hơn 0.5 và không thể các biến hóa xấu.
Như vậy, đối chiếu nhân tố khám phá EFA cho các biến độc lập được thực hiện hai lần. Lần trang bị nhất, 28 phát triển thành quan gần kề được đưa vào phân tích, có 2 trở nên quan giáp không đạt đk là DN4 cùng LD5 được vứt bỏ để tiến hành phân tích lại. Lần phân tích sản phẩm hai (lần cuối cùng), 26 biến quan sát quy tụ và rõ ràng thành 6 nhân tố.
3.2 Chạy EFA cho đổi thay phụ thuộc
Thực hiện nay tương tự các bước như cách làm với biến độc lập. Thay vày đưa phát triển thành quan sát của các biến tự do vào mục Variables, chúng ta sẽ đưa các biến quan ngay cạnh của biến phụ thuộc vào vào. Ví dụ trong ví dụ như này, biến nhờ vào Sự thích hợp gồm 3 đổi mới quan cạnh bên là HL1, HL2, HL3.
Kết trái output, họ cũng sẽ có được các bảng KMO và Barlett’s Test, Total Variance Explained,Rotated Component Matrix. Bảng
KMO và Barlett’s test giống trọn vẹn như đổi thay độc lập, phương pháp đọc hiệu quả cũng vậy.
Bảng Total Variance Explained lúc chỉ bao gồm một yếu tố được trích đang hiển thị như bên dưới (không bao gồm cột Rotation Sums of Squared Loadings). Trường phù hợp nếu tất cả từ hai yếu tố được trích, sẽ xuất hiện thêm thêm cột
Rotation Sums of Squared Loadings.

Kết trái phân tích cho biết thêm có một nhân tố được trích trên eigenvalue bằng 2.170 > 1. Yếu tố này lý giải được 72.339% đổi thay thiên tài liệu của 3 vươn lên là quan gần kề tham gia vào EFA.
Riêng bảng Rotated Component Matrixsẽ không lộ diện mà rứa vào đó được coi là dòng thông báo:Only one component was extracted. The solution cannot be rotated.

Điều này xẩy ra khi EFA chỉ trích được một yếu tố duy độc nhất vô nhị từ những biến quan ngay cạnh đưa vào. Dòng thông báo này trợ thời dịch là: Chỉ bao gồm một nhân tố được trích. Ma trận cần yếu xoay. Chúng ta luôn kỳ vọng gửi vào 1 biến phụ thuộc vào thì EFA cũng trở nên chỉ trích ra một nhân tố. Bài toán trích được chỉ một nhân tố là điều tốt, tức là thang đo đó bảo vệ được tính đối chọi hướng, các biến quan liền kề của biến phụ thuộc vào hội tụ tương đối tốt. Thời gian này, câu hỏi đọc tác dụng sẽ phụ thuộc bảng ma trận không xoay Component Matrix thay bởi vì bảng ma trận xoay
Rotated Component Matrix.
Không cần lúc nào ma trận xoay có được từ tác dụng phân tích EFA cũng tách bóc biệt các nhóm một bí quyết hoàn toàn, việc xuất hiện thêm các đổi thay xấu sẽ làm ma trận luân phiên bị xáo trộn so với các thang đo lý thuyết. Vậy phương pháp nhận diện thay đổi xấu và quy tắc loại vươn lên là xấu trong EFA như thế nào, mời các bạn xem tiếp ở bài bác viếtQuy tắc loại thay đổi xấu trong so sánh nhân tố khám phá EFA.
--------
Nếu bạn gặp khó khăn khi thực hiện phân tích EFA vì chưng số liệu khảo sát không tốt, chúng ta có thể tham khảodịch vụ so với SPSScủa Phạm Lộc Bloghoặc contact trực tiếp emailxulydinhluong
gmail.com. để tối ưu thời gian làm bài bác và đạt hiệu quả tốt.
Phân tích nhân tố tìm hiểu EFA là gì? Lấy hệ số tải Factor Loading từng nào mới là đúng? bí quyết tạo nhân tố và biến đại diện trong SPSS như thế nào? toàn bộ những thắc mắc này của các bạn sẽ được Luận Văn Việt chuyên dịch vụ SPSS uy tín sẽ câu trả lời trong nội dung bài viết này.

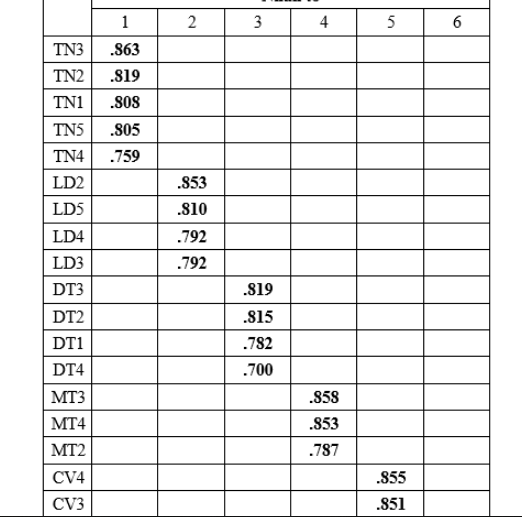
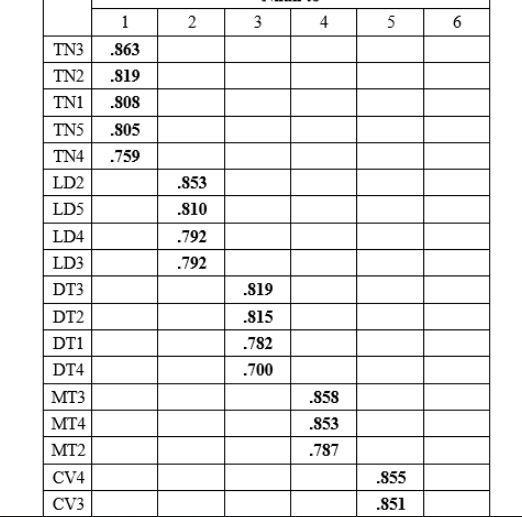
Ảnh 4 – Ma trận luân phiên nhân tố
Kết quả xoay nhân tố lần cuối chúng ta có được 6 nhân tố mới. Mỗi yếu tố sẽ gồm những biến thay mặt nằm bình thường trên 1 cột. Để tiến hành nhận xét tương quan Pearson với hồi quy, chúng ta sẽ phải lập các biến thay mặt đại diện trung bình trải qua lệnh Mean trong Compute Variable.
Ở đây, đưa sử các bạn tạo lần lượt những biến thay mặt đại diện là:
X1 = Mean (TN3, TN2, TN1, TN5, TN4)X2 = Mean (LD2, LD5, LD4, LD3)…..X6 = Mean (DN3, DN4, DN2)Thực hiện tại trên SPSS với quá trình sau:
Bước 1: Vào thẻ Transform > Compute Variable
Ảnh 5 – Tạo yếu tố đại diện
Giao diện cửa sổ mới hiển thị như hình dưới. Ở ô Target Variable, các các bạn sẽ gõ thương hiệu biến đại diện thay mặt mới (X1, X2, X3….). Mục Type và Label để các bạn điền vào chú thích đến biến, sứ mệnh của nó hệt như Lable khi các bạn tạo biến trong cửa sổ giao diện Variable View. Ví dụ đổi mới X1 là đại diện cho nhóm biến đổi quan sát: TN3, TN2….TN4, các bạn chú thích vươn lên là này là thay đổi Thu nhập thì vẫn gõ vào mục Type & Label.
Bước 2: Gõ cấu tạo hàm vào bảng
Ở ô Numeric Expression chúng ta gõ vào cấu tạo hàm: MEAN(TN3,TN2,TN1,TN5,TN4). Nghĩa là tạo thành biến đại diện thay mặt X1 là trung bình của các biến quan tiếp giáp TN3, TN2, TN1, TN5, TN4.
Ảnh 6 – Gõ kết cấu hàm vào bảng
Bảng kết quả
Sau khi chế tạo ra xong, các bạn vào lại đồ họa Data View các bạn sẽ thấy được những biến thay mặt đại diện vừa mới được sinh sản ra sát bên các biến hóa quan gần kề ban đầu:
Ảnh 7 – Bảng kết quả
Như vậy là chúng ta đã tạo hoàn thành các biến thay mặt đại diện sau khi so sánh EFA để sử dụng những biến này vào phân tích đối sánh Pearson cùng hồi quy về sau.
Xem thêm: Nhớ Những Câu Nói Hay Về Đoàn Thanh Niên Tình Nguyện, Tuổi Trẻ Đầy Nhiệt Huyết
Nếu bạn chạm chán khó khăn trong đối chiếu nhân tố mày mò EFA, chúng ta cũng có thể tham khảo dịch vụ cách xử lý số liệu SPSS của Luận văn Việt. Với tay nghề kinh nghiệm hơn 10 năm vận động trong lĩnh vực này, bọn chúng tôi chắc chắn là mang đến quality dịch vụ cũng như ngân sách phải chăng nhất mang lại bạn.